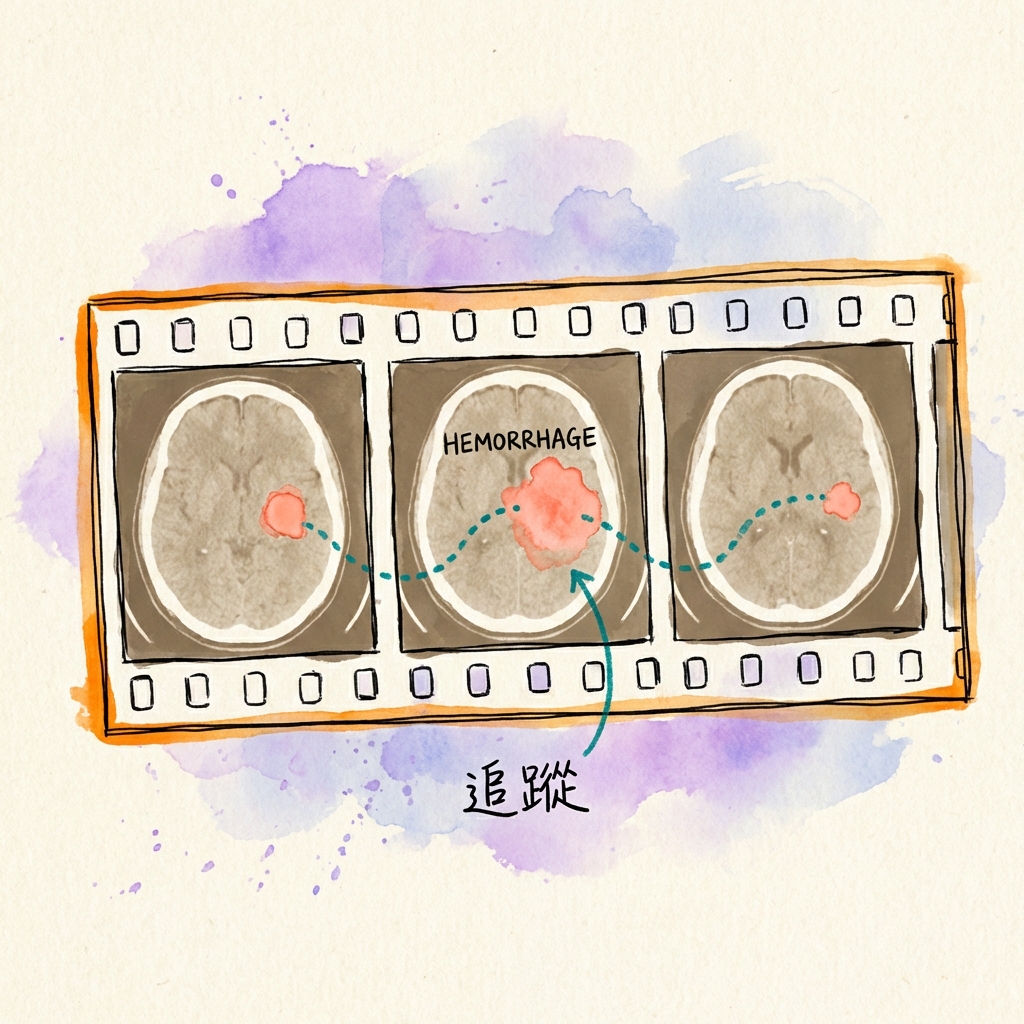
把 CT 掃描當影片看:用追蹤演算法偵測腦出血
放射科醫師看 CT 的時候,不是盯著一張固定的圖片——他們會滑過每一層切片,在腦海中「追蹤」病灶的連續性。伊朗 K.N. Toosi 理工大學的研究團隊把這個直覺變成了演算法:把 CT 的 z 軸當成時間軸,讓影片追蹤技術來驗證病灶是否真實存在。急診室的瓶頸:CT 量暴增,放射科醫師不夠用 過去幾年,急診室的 CT 使用量呈指數成長。問題是,放射科醫師的數量沒跟上。 這造成了一個危險的等待隊列——病人躺在那裡,腦出血可能正在惡化,但報告還沒出來。更糟的是,這個病人可能排在一堆「正常」的 CT 後面。 對於顱內出血(ICH)來說,診斷延遲直接關聯到不可逆的神經損傷和死亡率。 所以,這個 AI 系統的角色不是取代醫師寫報告,而是當自動分診員——掃描每一個進來的 CT,偵測到疑似出血就把它往前排,讓醫師優先處理最緊急的案例。 但要做到這一點,AI 得先解決一個問題:誤報。問題不是漏診,是誤報太多 現有的 2D 檢測器(如 YOLO)確實很敏感——一張切片有疑似出血,它就會標記。 但問題來了:它也會對骨頭邊緣、血管鈣化、掃描雜訊發出警報。 如果每個警報都讓醫師優先處理,很快就會警報疲勞——看到太多假警報,反而開始忽略。這比沒有 AI 還危險。 那 3D 卷積網路呢?它可以判斷「連續多張都有病灶」才發警報,但需要超大 GPU 記憶體(標準 3D CNN 動輒 50M+ 參數),沒辦法在救護車上或小型醫院的電腦跑。 這篇論文的解法:用追蹤演算法模擬 3D 連續性驗證——不需要真的做 3D 卷積,只要用影片追蹤的邏輯,過濾掉「只出現一張」的雜訊。把 CT 當影片:YOLO + ByteTrack 核心思路很簡單:放射科醫師滑過切片時會「追蹤」病灶,那 AI 也可以這樣做。 具體做法分兩層: 第一層:2D 檢測(YOLOv11n)每張切片獨立跑一次 YOLO,標記出疑似出血的區域 使用 Nano 版本(只有 2.6M 參數),比標準 3D CNN(50M+)輕了 20 倍以上第二層:跨切片追蹤(ByteTrack)把 CT 的 z 軸當成「時間軸」,每張切片就是一幀 ByteTrack 會追蹤同一個病灶在不同切片的位置 過濾邏輯:檢查第 z 張的標記與第 z-1、z+1 張是否有空間重疊(IoU > 0) 如果前後都沒有重疊→ 判定為孤立雜訊,過濾掉 如果前後至少有一張重疊→ 判定為真正病灶,保留額外技巧:雙向追蹤追蹤器有「暖機延遲」問題:演算法需要累積幾幀資訊才能確認軌跡,所以最初幾張切片可能會漏掉 解法:從頭到尾跑一遍,再從尾到頭跑一遍,兩次結果合併——這樣頭尾都不會漏結果:誤報少了,敏感度沒掉 研究團隊用 Hemorica 資料集做實驗(327 位病患,12,067 張切片)。 他們比較了兩種做法:基準線:只用 YOLO(每張切片獨立判斷,沒有前後記憶) 本論文方法:YOLO + 追蹤(先標記,再過濾掉孤立的雜訊)結果:指標 只用 YOLO YOLO + 追蹤Precision(精確度) 70.3% 77.9%Recall(敏感度) 64.3% 64.7%解讀(以切片為單位評估):精確度提升了 7.6 個百分點——代表誤報變少了 敏感度幾乎持平——代表沒有因為過濾而漏掉真正的病灶這對臨床有什麼用? 這套系統的目標是算力受限的環境:行動中風單位(救護車上的小型 CT) 偏遠地區的小型醫院這些地方的電腦跑不動 3D 卷積網路,但現在可以用這套輕量級方案:只需要 2.6M 參數的小模型 不需要高端 GPU 可以在標準硬體上即時運行核心價值:讓沒有高端設備的地方,也能做到即時分診判斷。 ⚠️ 限制與注意事項 這套方法並非萬能,以下情境可能會失效:小出血:只佔 1-2 張切片的微小出血,可能被當成「孤立雜訊」過濾掉 厚切層 CT:切片間距大時,病灶可能跨張不連續 高密度干擾:骨窗邊界、鈣化、對比劑殘留可能造成誤判 跨醫院泛化:測試集表現比訓練集下降(F1 從 0.974 降到 0.707),不同醫院的影像特性可能影響準確度總結 一個簡單的視角轉換——把 CT 的 z 軸當成時間軸——讓輕量級 AI 也能做到 3D 連續性驗證。 這套方法的優勢:輕量:只需要 2.6M 參數的小模型 有效:精確度從 70.3% 提升到 77.9% 不犧牲敏感度:真正的病灶不會被過濾掉對於資源受限的環境(如行動中風單位、偏遠醫院),這提供了一個可行的即時分診方案。放射師視角:能在自己醫院用嗎? 目前這是研究階段的概念驗證,沒有現成可下載的完整系統。 如果想部署到醫院,需要自行整合 PACS 接收影像,並建立通知機制發送警報給急診醫師。 開源資源(供有興趣的醫院自行研究):論文原文:arXiv:2601.02521 YOLO(物件偵測):Ultralytics GitHub ByteTrack(追蹤演算法):ByteTrack GitHub Hemorica 資料集:arXiv:2509.22993
AI 輔助肺結節偵測:最新技術與臨床應用
前言 肺癌是全球癌症死亡的主要原因之一,早期發現是提高存活率的關鍵。近年來,AI 輔助肺結節偵測技術快速發展,為放射科醫師提供了強大的輔助工具。 AI 技術突破 深度學習模型能夠在 CT 影像中自動識別微小結節(小於 5mm),準確率已超過 90%。這些技術不僅能偵測結節,還能預測其惡性機率。 臨床應用優勢提高偵測率:減少人為疏漏 標準化流程:統一診斷標準 節省時間:加速影像判讀未來展望 隨著技術進步和資料累積,AI 輔助診斷將成為放射科的標準配備,協助醫師做出更精準的判斷。

81.1% vs 61.1%——GPT-5.2 與開源模型的 RADS 分類準確率差距,能被縮小嗎?
為什麼放射科需要一套「共同語言」? 影像報告如果沒有標準化輸出,臨床端就很難得到明確的處置指引。RADS 系統就是為此而生——它把影像發現轉成統一的風險分級,讓後續決策有據可循。 舉個例子:乳房攝影看到一個結節,BI-RADS 2 表示「良性發現」,BI-RADS 5 則是「高度懷疑惡性,建議切片」。一個數字,臨床就知道下一步該怎麼做。 目前常用的 RADS 有十幾種:乳房的 BI-RADS、肝臟的 LI-RADS、前列腺的 PI-RADS……每一套都有自己的判斷邏輯。 但這些規則有多複雜? 以 LI-RADS 來說,判斷一顆肝臟腫瘤就像在玩一場「連續選擇題」:先看動脈期有沒有強化?有的話,洗出夠不夠快?有沒有包膜?門脈有沒有被侵犯?每一關的答案都會影響最終分類。光記住這張決策樹就夠累了,更別提每天幾十份報告等著處理。 如果 AI 能自動幫忙分類呢? 有團隊做了一個實驗:用 1,600 份模擬報告(由 AI 生成、再經放射科醫師審過),讓 41 個開源模型和 GPT-5.2 比賽,看誰能正確判讀 RADS 分類。 結果?最好的開源模型已經追到專有模型的 96%——但差距全集中在最難的那 20% 任務上。測試資料從哪來? 要比 AI 的能力,先得有一套標準考題。研究團隊準備了 1,600 份模擬放射報告,涵蓋 10 種 RADS 系統。為什麼用模擬的?因為真實報告有隱私問題,而且要請醫師一份一份讀、一份一份標正確答案,太花時間。模擬報告則可以控制每種情境的數量,測起來更全面。 怎麼確保「假報告」像真的?研究團隊用了三招:用多個 AI 模型(GPT、Claude、Gemini)一起生成,避免風格太單一 模擬 5 種醫師的寫作習慣(從資深專家到住院醫師) 最後請真人放射科醫師審兩輪,確認內容合理、分類正確當然,模擬再像也不是真的——這是這套測試的主要限制。模型大小,真的有差嗎? 這次測試了 41 個開源模型,參數量從 0.27B 到 32B 不等。加上 OpenAI 的 GPT-5.2 當作比較基準。 整體成績單 準確率比較:GPT-5.2:81.1% 開源模型平均:61.1% 最佳開源(20-32B):78%「有效輸出率」是什麼?就是模型有沒有按照指令、好好回答一個 RADS 分類。小模型常常答非所問,或格式錯誤——這在臨床上等於沒用。 10B 是個分水嶺 把模型按大小分組,規律很明顯:≤ 1B:27%(幾乎是亂猜) 1-10B:58% 10-30B:73-74% GPT-5.2:81%跨過 10B 門檻後,準確率才開始逼近 GPT-5.2。開啟「思考模式」有用嗎? 有些開源模型支援「Thinking mode」——讓 AI 先推理一輪再回答。 以開源模型來說:開啟 Thinking:68.4% 不開:56.5%差了 12%,效果明顯。 而 GPT-5.2 的 81.1% 準確率,也是在 Thinking 模式下測得的——所以「讓模型想一下再回答」這招,不管開源或專有模型都有效。「指引式提示詞」也很重要 除了 Thinking 模式,怎麼下指令也影響結果。 研究團隊比較了兩種方式:指引式提示詞(Guided prompting):給 AI 詳細的系統指令,包含 RADS 規則、輸出格式限制 零樣本提示(Zero-shot):只說「讀這份報告,輸出 RADS 分類」結果:指引式:78.5% 零樣本:69.6%差了將近 9%。所以不只是模型大小,怎麼問也很關鍵。哪些 RADS 最難判? 不是所有 RADS 都一樣難。研究團隊給每個系統打了「複雜度分數」,滿分 10 分。 複雜度排名:LI-RADS(肝臟 CT/MRI):10 分 ← 最難 PI-RADS(前列腺):9 分 O-RADS(卵巢 MRI):8 分 BI-RADS(乳房 MRI):7 分 Lung-RADS(肺):4 分 ← 相對簡單為什麼 LI-RADS 最難? 因為它像在玩「連續選擇題」:動脈期強化了嗎?洗出夠快嗎?有包膜嗎?每一關的答案都影響下一步。而且很多判斷帶有主觀性——「這算洗出嗎?」不同醫師可能有不同答案。 相比之下,Lung-RADS 主要依據結節大小和生長速度來分類,規則相對明確,判讀的主觀空間較小。 複雜度如何影響 AI 表現? 這裡差距最明顯: 高複雜度任務(LI-RADS、PI-RADS):GPT-5.2:90% 開源模型:49.4%低複雜度任務(Lung-RADS):GPT-5.2:91% 開源模型:73.5%簡單任務大家都還行,但一碰到複雜的,開源模型就掉隊了。 實務建議:怎麼選模型? 如果資源充足(硬體夠強、不在意 API 費用),直接用 GPT-5.2 或 32B 開源模型處理所有任務最省事。 但如果需要考慮成本、速度或本地部署限制,可以分級處理:簡單任務(Lung-RADS、LI-RADS 超音波)→ 10B+ 開源模型就夠用 中等任務(BI-RADS、TI-RADS)→ 20-32B 開源 + 指引式提示詞 複雜任務(LI-RADS CT/MRI、PI-RADS)→ GPT-5.2,或混合管線(AI + 規則引擎)結論:開源模型能用了嗎? 簡單說:可以,但要看情況。 值得期待的發展20-32B 開源模型已經能達到 GPT-5.2 約 96% 的準確率 可以本地部署,不用擔心病患資料外洩 搭配 Thinking 模式 + 指引式提示詞(Guided prompting),效果更好需要注意的限制高複雜度任務(LI-RADS CT/MRI、PI-RADS)開源模型仍有明顯差距 小模型(<10B)格式錯誤率高,不適合直接用 模擬報告畢竟不是真實報告,實際表現可能有落差如果你想在臨床試用驗證輸出格式:確保 AI 真的回答了一個 RADS 分類,不是答非所問 人工複核:特別是高風險類別(如 LI-RADS 5),一定要有人看過 混合管線:論文建議可以讓 AI 先抽取特徵,再用規則引擎(rule engine)做最終判定,減少自由格式輸出的錯誤論文資訊 原文標題:Multi-RADS Synthetic Radiology Report Dataset and Head-to-Head Benchmarking of 41 Open-Weight and Proprietary Language Models 來源:arXiv:2601.03232v1 [cs.CL] 6 Jan 2026 作者:Bose K, Kumar A, Soundararajan R, et al. 資源:GitHub - RadioX-Labs/RADSet
骨折 AI 自動標註系統:急診的智能助手
急診挑戰 急診室每天處理大量外傷病患,骨折診斷需要快速且準確。傳統方式完全依賴放射科醫師判讀,在高峰時段容易造成延遲。 AI 解決方案 骨折 AI 系統能在數秒內分析 X 光影像,自動標註可疑骨折區域,並依嚴重程度分級。系統整合 PACS,無縫融入現有工作流程。 實測成果偵測率:95% 以上 處理速度:平均 3 秒/張 漏診降低:減少 40%臨床價值 AI 不是取代醫師,而是作為「第二雙眼睛」,協助醫師在繁忙的急診環境中快速篩檢,確保沒有遺漏重要發現。 展望 未來將擴展至骨質疏鬆評估和骨齡判定,成為全方位的骨科影像分析平台。
腦出血影像分割:神經外科的即時決策工具
爭分奪秒的挑戰 急性腦出血是神經外科的緊急狀況,出血量和位置直接影響治療策略。傳統手動測量耗時且主觀性高。 AI 分割技術 3D U-Net 架構能自動分割出血區域,計算精確體積,並標示與重要腦區的關係。整個過程在 10 秒內完成。 關鍵優勢即時性:急診到報告不到 1 分鐘 精準度:體積誤差 < 5% 可量化:追蹤出血擴大情況臨床整合 系統與醫院 PACS 無縫整合,自動觸發分析並推送結果到神經外科會診系統,大幅縮短決策時間。 未來發展 結合預測模型,評估出血擴大風險,提供更全面的治療建議。
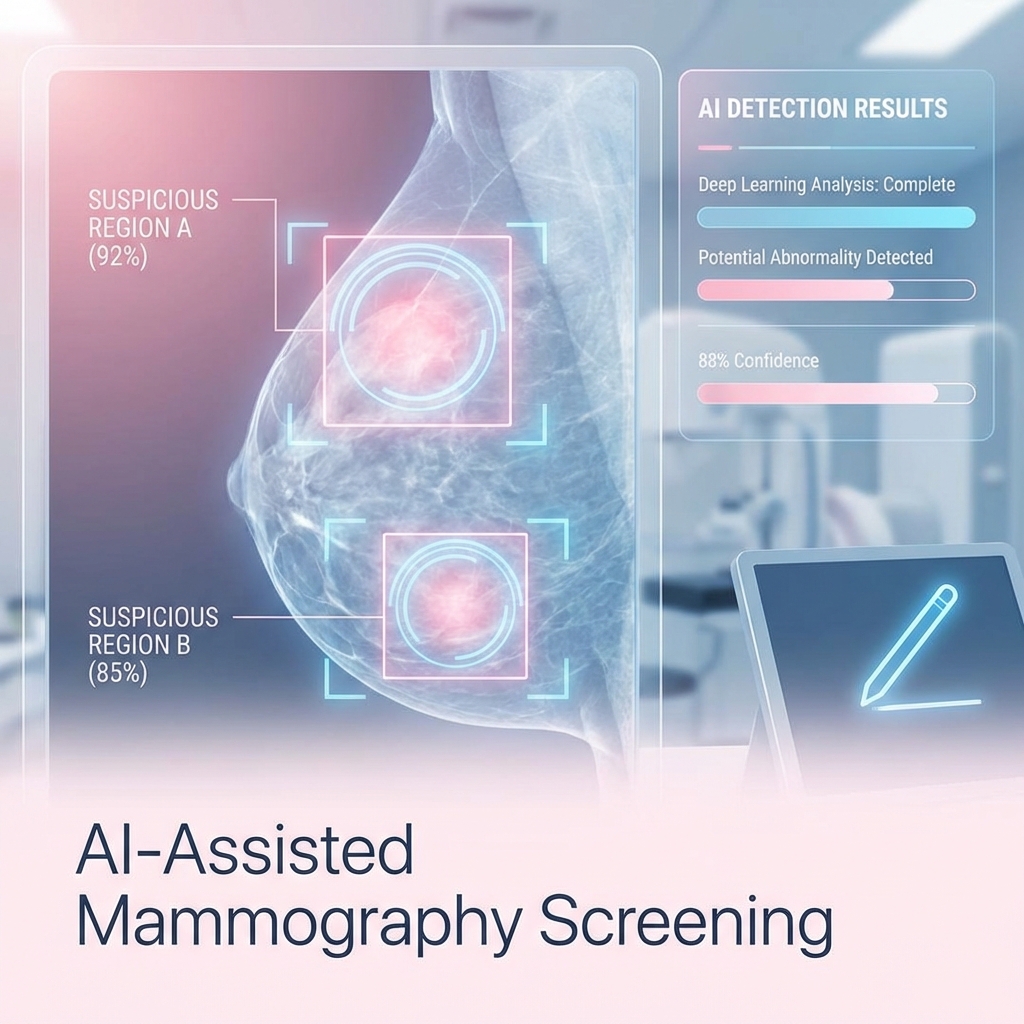
乳房攝影 AI 篩檢:提升早期乳癌偵測率
乳癌篩檢重要性 乳癌是女性常見癌症,早期發現存活率可達 90% 以上。乳房攝影是最有效的篩檢工具,但判讀需要專業經驗。 AI 輔助判讀 深度學習模型經過數十萬張影像訓練,能識別:微小鈣化(< 1mm) 不規則腫塊 組織密度異常雙重判讀機制 AI 系統作為「第一讀者」快速篩檢,標註可疑區域,放射科醫師進行「第二讀者」確認。這種雙重機制顯著降低漏診率。 臨床數據 大型研究顯示:偵測率提升 8-12% 召回率降低 5% 判讀時間減少 30%未來整合 結合 AI 風險評估模型,為高危險群提供個人化篩檢建議,實現精準預防醫學。